Supabase란 무엇인가? 웹페이지 SELECT, INSERT 실습
목적
- Supabase란 무엇인가?
- Firebase와의 차이점은 무엇인가?
- 웹페이지에서 데이터를 불러오고 삽입하기
- 구현하고자 하는 코드
- 발생한 문제
생활코딩의 Supabase 입문수업 - YouTube를 실습했습니다.
- 부딪혔던 문제와 해결법을 공유합니다.
Supabase란 무엇인가?
- 웹과 앱의 백앤드를 구현하기 위한 모든 기능을 제공하는 클라우드 서비스
- 데이터베이스 : ��데이터가 모여져 있는 공간으로 구조적인 방식으로 관리되는 데이터들의 집합
- 스토리지 : 업로드된 파일을 저장
- 인증기능 : 회원가입 및 로그인, 로그아웃 등
- Edge Function : 프로그래밍적으로 다양한 기능 처리 (장고, FastAPI 등이 수행하던)
구글의 Firebase와의 차이점
- Supabase는 데이터베이스를 관계형 데이터베이스인 PostgreSQL을 사용합니다.
Supabase의 계층

- 계정 (Account)
- 조직 (Organizations)
- 프로젝트 (Projects)
- 데이터베이스
- 스토리지
- 인증기능
- Edge functions
실습에서 만들고자 하는 서비스
- 슈파베이스를 통해 데이터베이스를 구축한다.
- title(text), body(text), create_at(date), id(int8) 컬럼을 만든다.
- 웹페이지를 통해 구축된 데이터베이스에서 불러와 렌더링한다.
- 웹페이지의 'Create' 버튼을 이용해서 새로운 'title'과 'body'를 입력받아 데이터베이스로 신규 데이터로 추가한다.

1. Supabase 가입하기

-
웹페이지에 들어가면, 나오는 대문 내용이 아주 맘에든다.
- 일주일안에 만들어서, 수백만에게 배포하기
-
회원가입을 해보자.

-
나는 GitHub으로 회원가입했다.
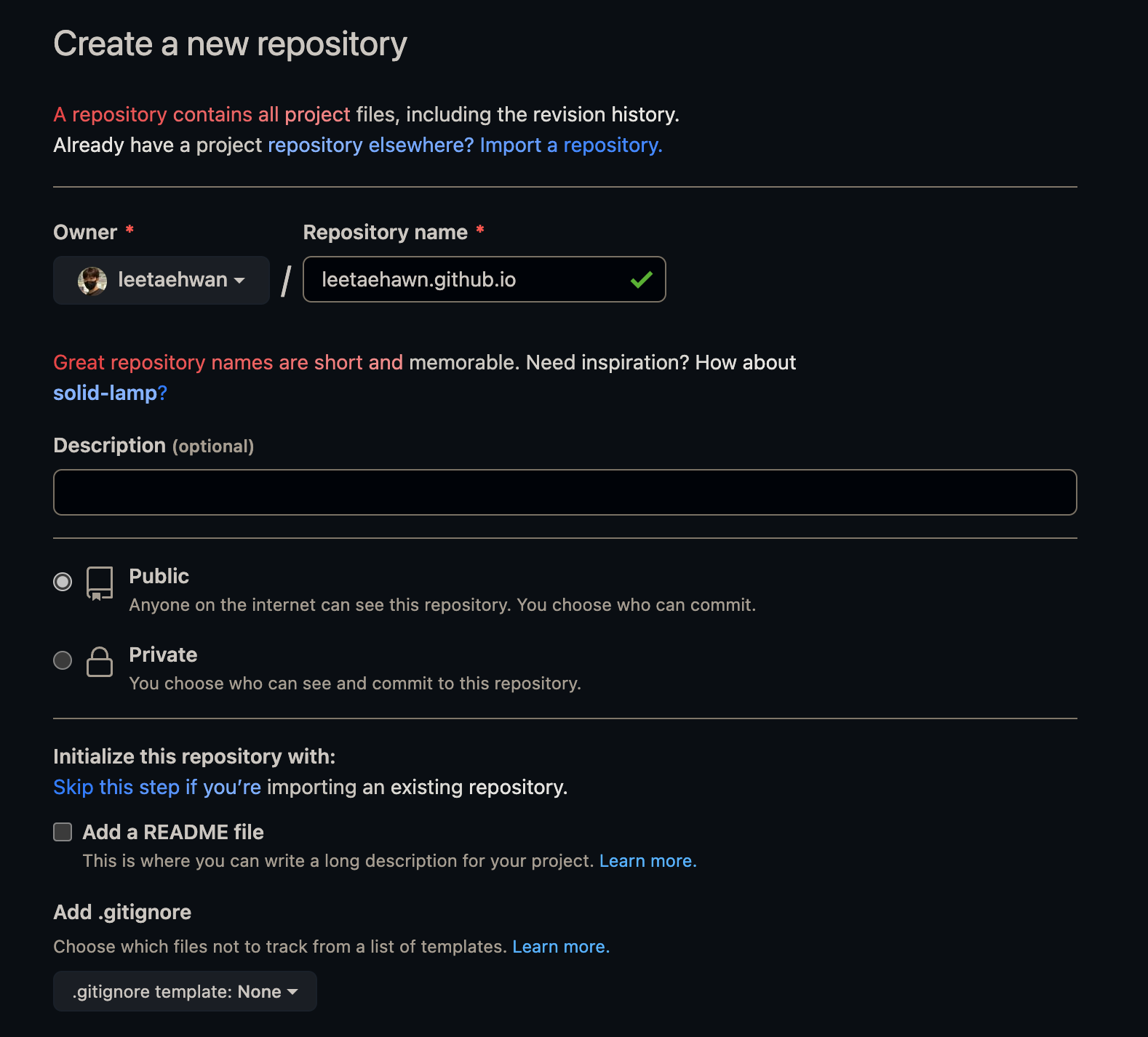
2. 프로젝트 만들기

- 프로젝트를 시작하기 위해서 'Start your project' 버튼을 눌러보자.
- 그러면 아래와 같은 대쉬보드가 나타난다.

- 이름을 사용한 기본값 조직이 생성되어 있을 것이다. 이 조직 안에 'New Project' 버튼을 눌러보자.

- 프로젝트 상위 조직을 지정한다.
- 프로젝트 이름을 정하고
- PostgreSQL의 데이터베이스의 암호를 입력한다.
- 나는 생성기를 통해서 생성했다. (따로 저장해두고 사용할 일을 거의 없다고 한다.)
- Region은 서비스가 배포될 지역과 가까운 곳으로 설정하자.
- 나는 한국에 서비스를 해야하니, 서울로 정한다.
- 위 내용들을 설정하면 이제 프로젝트가 만들어졌다.
3. 데이터 입력하기

- 프로젝트 생성을 마치면, 위와 같이 대쉬보드가 보입니다.
- 테이블 데이터를 만들어주기 위해서 '테이블 에디터' 버튼을 눌러줍니다.

- 'New table' 버튼을 눌러 새 테이블을 만듭시다.

- 기본값으로는 'RLS'가 활성화 되어있다.

- 처음에 RLS를 체크를 해제하고 아래와 같이 'page' 테이블을 만들었다.

- 이렇게 만든 테이블은 누구나에게 접근이 가능하게 된다고 경고가 나온다.
- RLS을 활성화 하지 않아서 그렇다.

- 'Insert' 버튼을 누르고, 'Insert row'를 눌러 데이터를 추가해보자.

- 'id'와 'create_at'은 자동으로 입력된다.
- 선택 영역인 'title'과 'body'를 예시로 입력하고 저장해보자.

- 'id'값이 1인 데이터가 하나 만들어졌다.
4. 웹서비스와 연결하기
- 웹페이지와 데이터베이스를 연결한 서비스를 만든다고 가정해보자.
- 완성된 예시 코드를 먼저 훑어보자.
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8" />
<meta name="viewport" content="width=device-width" />
<script src="https://cdn.jsdelivr.net/npm/@supabase/supabase-js@2"></script>
<title>JS Bin</title>
</head>
<body>
<h1>Supatodo</h1>
<div id="history"></div>
<input type="button" value="create" id="create_btn" />
<script>
const supabaseUrl = API의 url
const supabaseKey = API의 key
const client = supabase.createClient(supabaseUrl, supabaseKey)
async function refreshHistory() {
let { data: record, error } = await client.from('page').select('*');
console.log('record', record);
let tag = "";
for (let i = 0; i < record.length; i++) {
tag += `<h2>${record[i].title}</h2>${record[i].body}`;
}
document.querySelector('#history').innerHTML = tag;
}
refreshHistory()
async function recordHandler() {
const { data, error } = await client
.from('page')
.insert([
{ title: prompt("title?"), body: prompt("body?") }
]).select()
refreshHistory()
}
document.querySelector('#create_btn').addEventListener("click", recordHandler);
</script>
</body>
</html>
4-1. 웹페이지에 supabase 설치
- supabase의 도큐먼트 -> Installing을 보면 'package' 또는 'CDN'을 통한 설치 안내가 나와있다.
- 여기서는 CDN으로 supabase를 설치한다.
<script src="https://cdn.jsdelivr.net/npm/@supabase/supabase-js@2"></script>
//or
<script src="https://unpkg.com/@supabase/supabase-js@2"></script>
4-2. supabase API 연결하기

- 'API 문서' 탭을 들어가면, 'Introduction' 영역에서 우리가 API를 연결할 수 있는 코드가 제공된다.
- 웹페이지에서 패키지를 import하는 것이 까다롭기 때문에, 여기서는 사용하지 않는다.
- 대신에 CDN으로 설치하면 전역변수 supabase를 통해 기능을 접근할 수 있다.
- 'url'과 'key'가 입력되어야 한다.

- 이는 '설정 -> API'에 들어가면 볼 수 있다.
4-3. 테이블에서 데이터를 읽어오기

- 'Introduction' 항목 밑에 우리가 만든 테이블 이름을 고를 수 있다.
- 밑으로 스크롤을 좀 내리면 'Read rows' 영역에 'READ ALL ROWS'의 코드가 있다.
- 이 비동기(await) 코드를 async 함수에 넣어서 사용해주면 데이터를 불러와 콘솔에 출력시켜볼 수 있다.
async function refreshHistory() {
let { data: record, error } = await client.from('page').select('*');
console.log('record', record);
4-4. 웹페이지 div 태그에 불러온 데이터 삽입하기
- 데이터를 읽은 수 만큼 할당하는 동적할당을 위해서 for문을 사용한다.
- for문으로 record를 반복해서 title과 body를 문자열 tag에 담아준다.
- 완성된 tag를 querySelector()를 통해서 div를 선택햬서, innerHTML에 넣어준다.
let tag = "";
for (let i = 0; i < record.length; i++) {
tag += `<h2>${record[i].title}</h2>${record[i].body}`;
}
document.querySelector("#history").innerHTML = tag;
4-5 웹페이지에 'create' 버튼으로 데이터베이스에 데이터 추가하기
- 아까 읽어온 것처럼 'API 문서'의 테이블에 들어가서 'INSERT A ROW'의 코드를 가져온다.

- 위 코드를 가져와서 async 함수에 넣어준다.
- 위에서 some_column과 other_column에 우리가 넣고자 하는 데이터베이스의 컬럼 값을 넣어준다.
- 그리고 'someValue'와 'otherValue'에 넣고자 하는 값을 넣어준다.
- 여기서는 prompt를 입력받아서 데이터를 삽입해주고 페이지에 랜더링한다.
async function recordHandler() {
const { data, error } = await client
.from("page")
.insert([{ title: prompt("title?"), body: prompt("body?") }])
.select();
refreshHistory();
}
document.querySelector("#create_btn").addEventListener("click", recordHandler);
- 여기까지 supabase 입문에 대해 알아보는 것을 마친다.
결론
- supabase를 가입
- 프로젝트를 만들고
- table을 만들어 웹페이지에서 불러와(SELECT) 랜더링
- 웹페이지에서 table의 데이터를 삽입(INSERT)

 한 줄로 나와서 보기가 불편하다.
한 줄로 나와서 보기가 불편하다.